🚀 From Google Podcasts to Moon FM in No Time: Your Hassle-Free Migration Guide
👉

Hacker Public Radio is an podcast that releases shows every weekday Monday through Friday. Our shows are produced by the community (you) and can be on any topic that are of interest to hackers and hobbyists.
I have been struggling with my body weight since I was 35, and I’m
now 60.
I know that not all listeners are familiar with the kilogram as unit of
measurement, but we can use the BMI (Body Mass Index) formula to discuss
this. It should be somewhere between 22 and 25 and mine has been 33 for
a long time. A very long time. No matter what I tried.
Yes, I tried some diets but they only work if you keep doing them. So
if something does not become normal or easy than at some inevitable
point you will stop and gain weight again.
Yes, they talk about changing your life style but any change that is too
drastic is bound to fail in the end.
And then recently I read this book. This absolutely changed my life and that is why I am so motivated to tell you all about it.
Book obesity code, Jason Fung, a Canadian nephrologist (kidney
specialist).
He is also a functional medicine advocate who promotes a
low-carbohydrate high-fat diet and intermittent fasting. But we come
back to that later.
Not another diet hype. That is an industry on its own.
This is scientific stuff. With lots of links to research papers.
With large groups and thoroughly peer reviewed.
And this does not mean that this story is for everyone.
There exist other medical reasons why people gain weight.
But, assuming most people start out in life being healthy, then most
people gaining weight are not ill.
So, if you gain weight, consult your doctor first to rule out any
medical reasons.
Jason Fung noticed that practice didn't match with theory.
Everybody who is given insulin gains weight.
Even diabetes type 2 people.
There are even several scientific studies that proves this. Give people
insulin and they will gain weight.
So what if insulin is the culprit for gaining weight?
Insulin is a hormone. Its job is to send signals through the body.
Its use is to allow body cells to absorb nutrients in the blood
stream.
Every time you eat the insulin peaks and subsides normally three times a day.
Body process called gluconeogenesis. Making fat in the liver for one day storage.
If you eat the body makes insulin. That is normal.
If you eat more, the body makes more insulin.
Body cells adjust to the higher level and become tone deaf to insulin:
Insulin resistant.
This means next time the insulin level needs to be higher.
And higher levels of insulin mean you will gain weight.
If you eat sugar, it is so easy to break down that it goes immediately into storage, e.g. body fat.
The thing is, wheat is chemically a long string of sugars. So the body will break it down into sugar and send that too to storage.
And almost any food we buy these days contains sugar.
Except unprocessed foods like vegetables.
How to lose weight? Well, the body needs to access the fat in storage. So we need to extend not eating until the liver has run dry of the daily dose of liver fat.
This is very easy. Just extend the daily period that you do not
eat.
When do you not eat? When you sleep. So, skip breakfast. The name says
it all, you are breaking your fast.
Drink some coffee (no sugar of course), or tea, or water and try to start eating later in the day.
And another word for not eating is fasting. But it is a voluntary fast!
So I tried this for one day. Skip breakfast and try to eat it at noon. I mean, what could possibly go wrong, right? The next day I had lost some weight. And it was sooo easy! I could say 300 grams but again, your mileage may vary or you have no clue what one gram is, let alone 300. But that is not the point. The point is that I lost weight! And to me this has been super easy.
So the solution turns out to be:
Which brings me to food categories.
Average digestion times of
How has all this theory changed my life and diet?
Since I started 2 month ago I have on average lost 4 kilograms. It could have been more but then there’s the occasional dinner with friends and what is bad, but soo good, is unavoidable.
So, some other stuff that is good to know:
What’s that about exercising?
What’s with the calories in are calories out? Studies have proven that this is a false claim. It just doesn't work that way.
What about stress. Well, it turns out that stress leads to heightened levels of the hormones adrenaline and cortisol. And when cortisol rises, so too does the insulin levels in your body. So, this simply means that stress will lead to weight gain.
Can I simply drink diet sodas. Well, bummer there, because although it diet sodas do not contain calories nor sugars, they will result in a rise in your insulin level, so they are not good for loosing weight.
[The Diary Of A CEO with Steven Bartlett] The Fasting Doctor: “Fasting Cures Obesity!”, This Controversial New Drug Melts Fat, Fasting Fixes Hormones! Skip Breakfast!
https://podcasts.apple.com/gb/podcast/the-fasting-doctor-fasting-cures-obesity-this/id1291423644
Jason Fung YouTube channel, https://www.youtube.com/watch?v=8RuWp3s6Uxk
I hope you found this explanation helpful. Have a nice day.
This is the start of a short series about the JSON data format, and how the command-line tool jq can be used to process such data. The plan is to make an open series to which others may contribute their own experiences using this tool.
The jq command is described on the GitHub page as follows:
jq is a lightweight and flexible command-line JSON processor
…and as:
jq is like sed for JSON data - you can use it to slice and filter and map and transform structured data with the same ease that sed, awk, grep and friends let you play with text.
The jq tool is controlled by a programming language (also referred to as jq), which is very powerful. This series will mainly deal with this.
To begin we will look at JSON itself. It is defined on the Wikipedia page thus:
JSON is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute–value pairs and arrays (or other serializable values). It is a common data format with diverse uses in electronic data interchange, including that of web applications with servers.
The syntax of JSON is defined by RFC 8259 and by ECMA-404. It is fairly simple in principle but has some complexity.
JSON’s basic data types are (edited from the Wikipedia page):
Number: a signed decimal number that may contain a fractional part and may use exponential E notation, but cannot include non-numbers. (NOTE: Unlike what I said in the audio, there are two values representing non-numbers: 'nan' and infinity: 'infinity'.
String: a sequence of zero or more Unicode characters. Strings are delimited with double quotation marks and support a backslash escaping syntax.
Boolean: either of the values true or false
Array: an ordered list of zero or more elements, each of which may be of any type. Arrays use square bracket notation with comma-separated elements.
Object: a collection of name–value pairs where the names (also called keys) are strings. Objects are delimited with curly brackets and use commas to separate each pair, while within each pair the colon ':' character separates the key or name from its value.
null: an empty value, using the word null
These are the basic data types listed above (same order):
42 "HPR" true ["Hacker","Public","Radio"] { "firstname": "John", "lastname": "Doe" } nullFrom the Wikipedia page:
jq was created by Stephen Dolan, and released in October 2012. It was described as being “like sed for JSON data”. Support for regular expressions was added in jq version 1.5.
This tool is available in most of the Linux repositories. For example, on Debian and Debian-based releases you can install it with:
sudo apt install jqSee the download page for the definitive information about available versions.
There is a detailed manual describing the use of the jq programming language that is used to filter JSON data. It can be found at https://jqlang.github.io/jq/manual/.
This is a collection of statistics about HPR, in the form of JSON data. We will use this as a moderately detailed example in this episode.
A link to this page may be found on the HPR Calendar page close to the foot of the page under the heading Workflow. The link to the JSON statistics is https://hub.hackerpublicradio.org/stats.json.
If you click on this you should see the JSON data formatted for you by your browser. Different browsers represent this in different ways.
You can also collect and display this data from the command line, using jq of course:
$ curl -s https://hub.hackerpublicradio.org/stats.json | jq '.' | nl -w3 -s' ' 1 { 2 "stats_generated": 1712785509, 3 "age": { 4 "start": "2005-09-19T00:00:00Z", 5 "rename": "2007-12-31T00:00:00Z", 6 "since_start": { 7 "total_seconds": 585697507, 8 "years": 18, 9 "months": 6, 10 "days": 28 11 }, 12 "since_rename": { 13 "total_seconds": 513726307, 14 "years": 16, 15 "months": 3, 16 "days": 15 17 } 18 }, 19 "shows": { 20 "total": 4626, 21 "twat": 300, 22 "hpr": 4326, 23 "duration": 7462050, 24 "human_duration": "0 Years, 2 months, 27 days, 8 hours, 47 minutes and 30 seconds" 25 }, 26 "hosts": 356, 27 "slot": { 28 "next_free": 8, 29 "no_media": 0 30 }, 31 "workflow": { 32 "UPLOADED_TO_IA": "2", 33 "RESERVE_SHOW_SUBMITTED": "27" 34 }, 35 "queue": { 36 "number_future_hosts": 7, 37 "number_future_shows": 28, 38 "unprocessed_comments": 0, 39 "submitted_shows": 0, 40 "shows_in_workflow": 15, 41 "reserve": 27 42 } 43 }The curl utility is useful for collecting information from links like this. I have used the -s option to ensure it does not show information about the download process, since it does this by default. The output is piped to jq which displays the data in a “pretty printed” form by default, as you see. In this case I have given jq a minimal filter which causes what it receives to be printed. The filter is simply '.'. I have piped the formatted JSON through the nl command to get line numbers for reference.
The JSON shown here consists of nested JSON objects. The first opening brace and the last at line 43 define the whole thing as a single object.
Briefly, the object contains the following:
We will look at ways to summarise and reformat such output in a later episode.
I will look at some of the options to jq next time, though most of them will be revealed as they become relevant.
I will also start looking at jq filters in that episode.
Awesome mpv resources on Github
MPV History using Lua on my Github page
I give a quick tip on shortcut keys for watching Youtube or other video sites in MPV
hpr3133 :: Quick tip - Using MPV
https://docs.google.com/document/d/17z3i5VlRzEn2tYPfb-Cx0LYpdKkbL-6svIzp7ZQOvX8
I use Kagi.com pro $300 / year but you get access to much more Search+AI but not plugins like ChatGPT so if you MUST have ChatGPT plugins you will need OpenAI Premium account but if you don't I high recommend Kagi.com Pro account with access to Assistant Beta !!!
Land a Job using ChatGPT: The Definitive Guide!
https://youtu.be/pmnY5V16GSE?t=192
Extensive Resume Notes
https://drive.google.com/file/d/1zeYIG7tTE0BUqbRM7-hpk3VdTRc35ZkL/view?usp=sharing
Ripped cybersn
https://rmccurdy.com/.scripts/downloaded/knowmore.cybersn.com_20220811.txt
Perfect ChatGPT Prompt
https://www.youtube.com/watch?v=jC4v5AS4RIM
There is a formula consisting of 6 building blocks that can help generate high quality outputs from ChatGPT and Google Bard: task, context, exemplars, persona, format, and tone.
The order of importance for the building blocks is task first, then context, with the others being optional but helpful.
The task should clearly articulate the end goal using an action verb like "generate" or "analyze".
Context provides relevant background information to constrain possibilities.
Exemplars like examples or frameworks included in the prompt can improve output quality.
The persona allows specifying who ChatGPT should be, like a job recruiter.
The format specifies how the output should be structured, like an email or bullet points. Tone provides keywords to set the feeling, like "friendly" or "serious".
You are a senior product marketing manager at Apple and you have just unveiled the latest Apple product in collaboration with Tesla, the Apple Car, and received 12,000 pre-orders, which is 200% higher than target. Write an email to your boss, Tim Cookie, sharing this positive news. The email should include a tl;dr (too long, didn't read) section, project background (why this product came into existence), business results section (quantifiable business metrics), and end with a section thanking the product and engineering teams. Use clear and concise language and write in a confident yet friendly tone.
I want you to act as a cyber security specialist for a leading consumer products company and you want to relay the importance of people understanding their data and have some idea what they want to do with it before we spend hours for the onboarding effort. Write an email to your boss, Joey , sharing this critical component of the SIEM. The email should include a tl;dr (too long, didn't read) section, example of how the team can spend many cycles onboarding data only to find the requester has no idea what they want to do with the data or it does not satisfy their use case. Use clear and concise language and write in a confident yet friendly tone.
Response Subject: Streamlining SIEM Onboarding with
Clear Data Objectives
Hi Joey,
I hope this email finds you well. I wanted to touch base on a critical aspect of our Security Information and Event Management (SIEM) process that could significantly enhance our efficiency.
TL;DR: We need to ensure that stakeholders understand their data and have clear objectives before we initiate the SIEM onboarding process. This will prevent the team from spending excessive time onboarding data that may not meet the intended use cases or for which the requester has no actionable plan.
During our recent SIEM onboarding efforts, we've encountered several instances where considerable time and resources were invested in integrating data sources, only to discover that the requesters were unclear about their objectives or the data did not fulfill their anticipated needs. For example, last month, the team dedicated over 40 hours to onboarding a new data source for the marketing department. After completion, it became apparent that the marketing team was unsure how to leverage this data for threat detection or compliance reporting, rendering the effort less effective.
To address this, I propose we implement a preliminary consultation phase for each SIEM onboarding request. In this phase, requesters must articulate: - The specific security or compliance questions they aim to answer with the data. - How they intend to use the data within the SIEM environment. - Any particular data formats or schemas they anticipate will be necessary.
By doing so, we can align our onboarding efforts with the actual needs and ensure that every hour spent is towards enhancing our security posture and providing actionable insights.
I believe this approach will not only save time but also empower our stakeholders to make better-informed decisions regarding their security data needs.
Looking forward to your thoughts on this.
Best regards,
[Your Name]
Cyber Security Specialist
ProfSynapse AI Agent
Video: https://www.youtube.com/watch?v=BL9x1SuNLRo&t=137s
( if you have Openai Premium it will use [tools(Vision, Web Browsing,
Advanced Data Analysis, or DALL-E],
( https://raw.githubusercontent.com/ProfSynapse/Synapse_CoR/main/GPTprompt.txt
)
GPT Agents (old)
https://godmode.space/
needs openai key and gpt4 also enable auto approval it may go in loops
just watch for that
AutoGPT ( OLD )
Image
I have a stupid amount of kudos
Use my key under the settings for any of the web UI's for faster renders:
https://rentry.org/RentrySD/#x-table-of-contents https://rentry.org/sdhypertextbook
https://github.com/C0untFloyd/bark-gui ( Audio Clone )
Example 1
Photorealistic, best quality, masterpiece, raw photo of upper body photo, Swordsman woman, soldier of the austro-hungarian empire clothes, double breasted jacket with stripes, extremely detailed eyes and face, long legs, highest quality, skin texture, intricate details, (cinematic lighting), RAW photo, 8k
Negative prompt: airbrush, photoshop, plastic doll, plastic skin, easynegative, monochrome, (low quality, worst quality:1.4), illustration, cg, 3d, render, anime
Text Generation
Example Open source Projects:
my hord key : l2n6qwRBqXsEa_BVkK8nKQ ( don't abuse but I have a crazy
amount of kudos don't worry )
https://tinybots.net/ Image Text etc ..
Text adventures etc (Click the horde tab and use my key) https://agnai.chat/settings?tab=0 https://lite.koboldai.net
Need a 24G NVRAM card really..you can load 7b with my 8G card just fine. ollama run wizard-vicuna-uncensored, falcon, Mistral 7B
"You should have at least 8 GB of RAM to run the 3B models, 16 GB to run the 7B models, and 32 GB to run the 13B models."
https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/
https://github.com/xtekky/gpt4free https://www.thesamur.ai/autogpt https://poe.com/universal_link_page?handle=ChatGPT https://camelagi.thesamur.ai/conversation/share?session=6040
Prompt Agent Persona example 1
Pinky from the TV Series Pinky and the Brain
I find it easiest to understand responses when the text is written as if it was spoken by a Pinky from the TV Series Pinky and the Brain. Please talk like Pinky from the TV Series Pinky and the Brain as much as possible, and refer to me as "Brain"; occasionally, ask me "What are we going to do tonight Brain ?"
Prompt Agent Persona example 2
Use with prompts to create a persona take Myers-Brigg personality and tritype Enneagram quiz:
Example Prompt:
Help me Refine my resume to be more targeted to an information security engineer. Be sure to be clear and concise with with bullet points and write it in the style of MBTI Myers-Brigg personality ENFJ and tritype Enneagram 729
Prompt Agent Persona example 3 I find it easiest to understand responses when the text is written as if it was spoken by a dudebro. Please talk like a dudebro as much as possible, and refer to me as "Brah"; occasionally, yell at your dorm roommate Jake about being messy.
Training (OLD OLD OLD )
3 photos of full body or entire object + 5 medium shot photos from the chest up + 10 close ups astria.ai
https://github.com/TheLastBen/fast-stable-diffusion/issues/1173
colab: https://github.com/TheLastBen/fast-stable-diffusion
pohtos: 21
resolution: 768
merged with ##### 1.5 full 8G
UNet_Training_Steps: 4200
UNet_Learning_Rate: 5e-6
Text_Encoder_Training_Steps: 2520
Text_Encoder_Learning_Rate: 1e-6
Variation is key - Change body pose for every picture, use pictures from different days backgrounds and lighting, and show a variety of expressions and emotions.
Make sure you capture the subject's eyes looking in different directions for different images, take one with closed eyes. Every picture of your subject should introduce new info about your subject.
Whatever you capture will be over-represented, so things you don't want to get associated with your subject should change in every shot. Always pick a new background, even if that means just moving a little bit to shift the background.
Here are 8 basic tips that work for me, followed by one super secret tip that I recently discovered.
Consistency is important. Don’t mix photos from 10 years ago with new ones. Faces change, people lose weight or gain weight and it all just lowers fidelity.
Avoid big expressions, especially ones where the mouth is open.
It is much easier to train if the hair doesn't change much. I tried an early model of a woman using photos with hair up, down, in ponytail, with a different cut, etc. It seems like it just confused SD.
Avoid selfies (unless you ONLY use selfies.) There is MUCH more perspective distortion when the camera is that close. For optimal results, a single camera with a fixed lens would be used, and all photos should be taken at the same distance from the subject. This usually isn't possible, but at least avoid selfies because they cause major face distortion.
Full body shots are not that important. Some of the best models I trained used only 15 photos cropped to the head / shoulder region. Many of these were full body shots, but I cropped them down. SD can guess what the rest of the body looks like, and if not, just put it in the prompts. The only thing hard to train is the face, so focus on that.
I no longer use any profile shots as they don’t seem to add value. I like to have a couple looking slightly left and a couple looking slightly right (maybe 45 degrees.) All the rest can be straight at the camera. Also, try to avoid photos taken from really high or low angles.
If possible, it’s good to have some (but not all) of the photos be on a very clean background. On my last batch, I used an AI background removal tool to remove the background from 1/4 of the photos and replaced it with a solid color. This seemed to improve results.
Careful with the makeup. It should be very consistent across all the photos. Those cool “contour” effects that trick our eyes, also trick SD.
Interview from a very smart autodidact
https://youtu.be/AaTRHFaaPG8?t=3279
Canva AI Presentation generator
https://www.youtube.com/watch?v=Nl2gLi1MD04
Charleston, South Carolina is a classic Southern city which had a past as a wealthy city, in large part due to slavery, and was active in the American Revolution before becoming the starting place of the Civil War.
This is the first episode in a new series called Home Automation. The series is open to anyone and I encourage everyone to contribute.
https://en.wikipedia.org/wiki/Home_automation From Wikipedia, the free encyclopedia
Home automation or domotics is building automation for a home. A home automation system will monitor and/or control home attributes such as lighting, climate, entertainment systems, and appliances. It may also include home security such as access control and alarm systems.
The phrase smart home refers to home automation devices that have internet access. Home automation, a broader category, includes any device that can be monitored or controlled via wireless radio signals, not just those having internet access. When connected with the Internet, home sensors and activation devices are an important constituent of the Internet of Things ("IoT").
A home automation system typically connects controlled devices to a central smart home hub (sometimes called a "gateway"). The user interface for control of the system uses either wall-mounted terminals, tablet or desktop computers, a mobile phone application, or a Web interface that may also be accessible off-site through the Internet.
I tried this out a few years ago, but after a lot of frustration with configuration of esp32 arduinos, and raspberry pi's I left it be. Recently inspired by colleagues in work, I decided to get back into it and my initial tests show that the scene has much improved over the years.
The first thing we'll need is something to control it all. Something will allow us to control our homes without requiring the cloud.
https://en.wikipedia.org/wiki/Home_Assistant From Wikipedia, the free encyclopedia
Home Assistant is free and open-source software for home automation, designed to be an Internet of things (IoT) ecosystem-independent integration platform and central control system for smart home devices, with a focus on local control and privacy. It can be accessed through a web-based user interface, by using companion apps for Android and iOS, or by voice commands via a supported virtual assistant, such as Google Assistant or Amazon Alexa, and their own "Assist" (built-in local voice assistant).
The Home Assistant software application is installed as a computer appliance. After installation, it will act as a central control system for home automation (commonly called a smart home hub), that has the purpose of controlling IoT connectivity technology devices, software, applications and services from third-parties via modular integration components, including native integration components for common wireless communication protocols such as Bluetooth, Thread, Zigbee, and Z-Wave (used to create local personal area networks with small low-power digital radios). Home Assistant as such supports controlling devices and services connected via either open and proprietary ecosystems as long they provide public access via some kind of Open API or MQTT for third-party integrations over the local area network or the Internet.
Information from all devices and their attributes (entities) that the application sees can be used and controlled from within scripts trigger automation using scheduling and "blueprint" subroutines, e.g. for controlling lighting, climate, entertainment systems and home appliances.
The following is taken from the Concepts and terminology on the Home Assistant website. It is reproduced here under the creative commons Attribution-NonCommercial-ShareAlike 4.0 International License
Integrations are pieces of software that allow Home Assistant to connect to other software and platforms. For example, a product by Philips called Hue would use the Philips Hue term integration and allow Home Assistant to talk to the hardware controller Hue Bridge. Any Home Assistant compatible term devices connected to the Hue Bridge would appear in Home Assistant as devices.
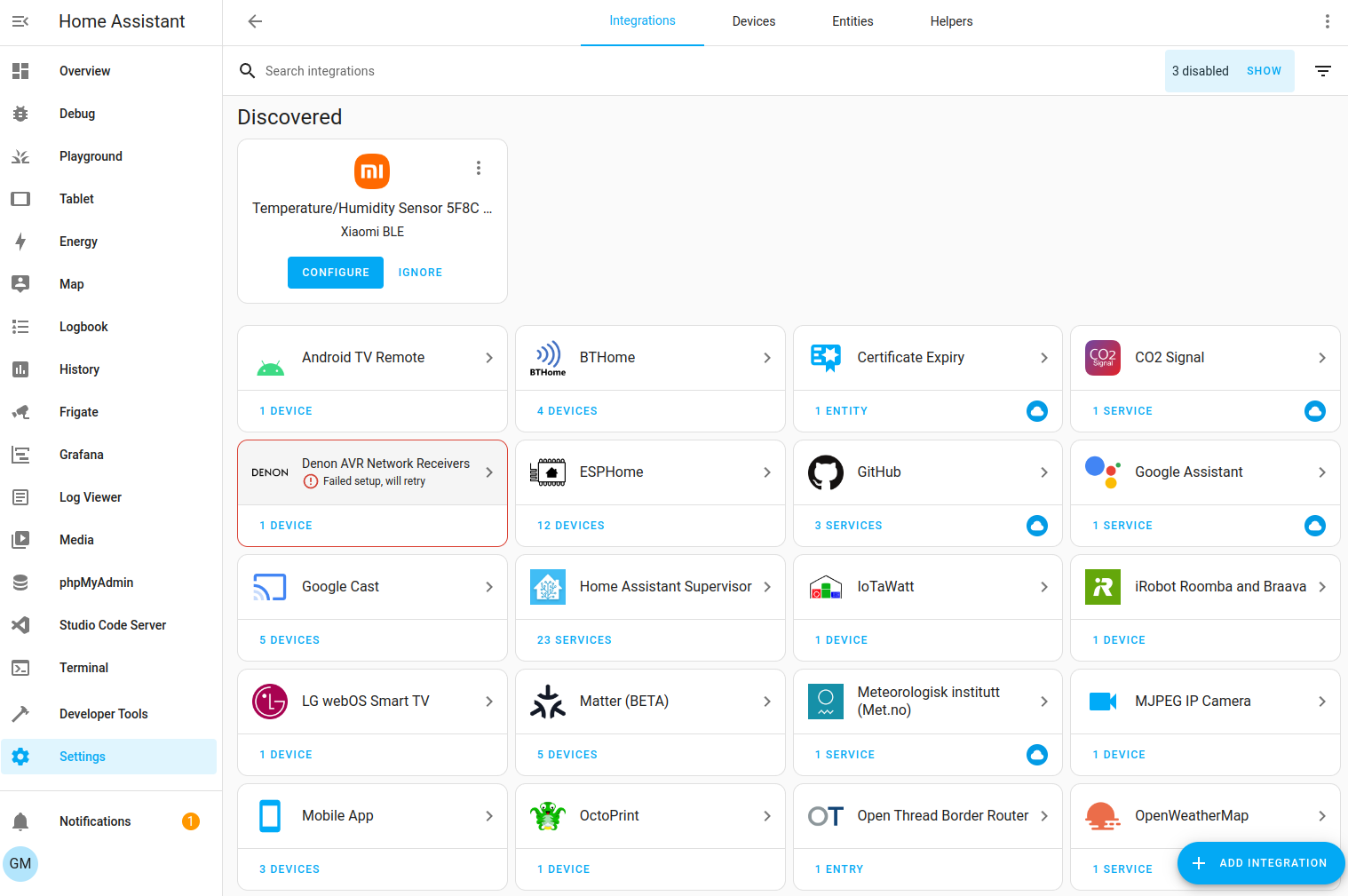
For a full list of compatible term integrations, refer to the integrations documentation.
Once an term integration has been added, the hardware and/or data are represented in Home Assistant as devices and entities.
Entities are the basic building blocks to hold data in Home Assistant. An term entity represents a term sensor, actor, or function in Home Assistant. Entities are used to monitor physical properties or to control other term entities. An term entity is usually part of a term device or a term service. Entities have term states.
Devices are a logical grouping for one or more term entities. A term device may represent a physical term device, which can have one or more sensors. The sensors appear as entities associated with the term device. For example, a motion sensor is represented as a term device. It may provide motion detection, temperature, and light levels as term entities. Entities have states such as detected when motion is detected and clear when there is no motion.
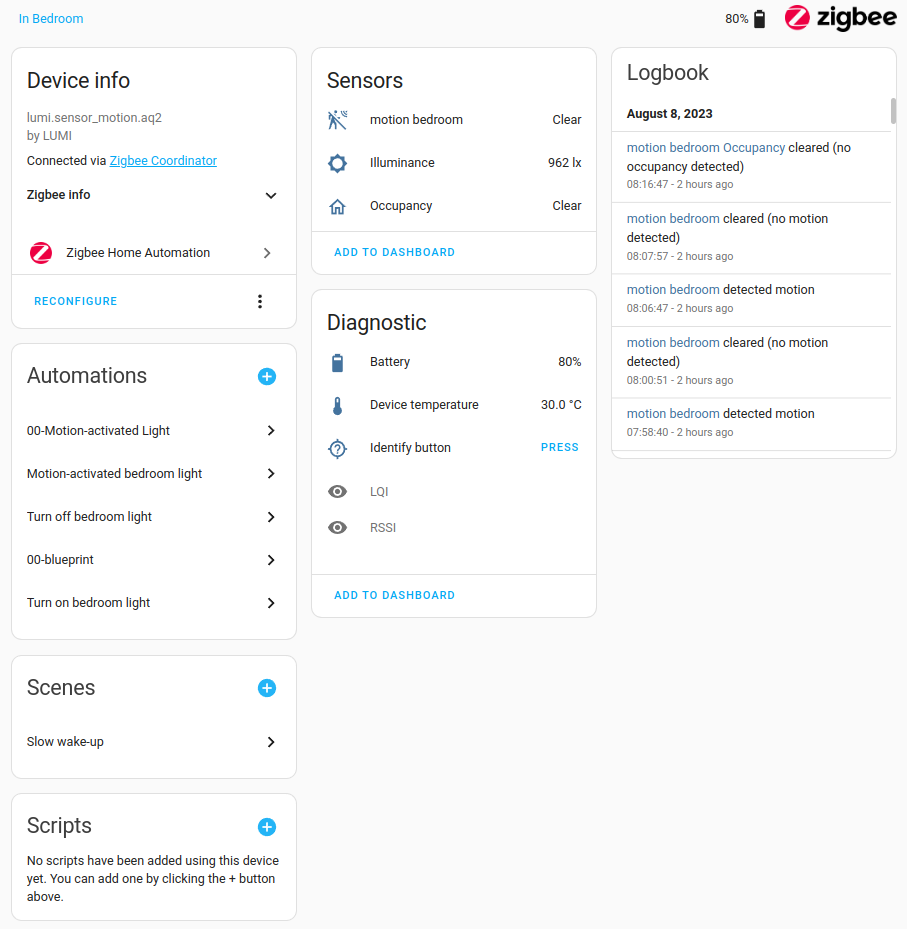
Devices and entities are used throughout Home Assistant. To name a few examples:
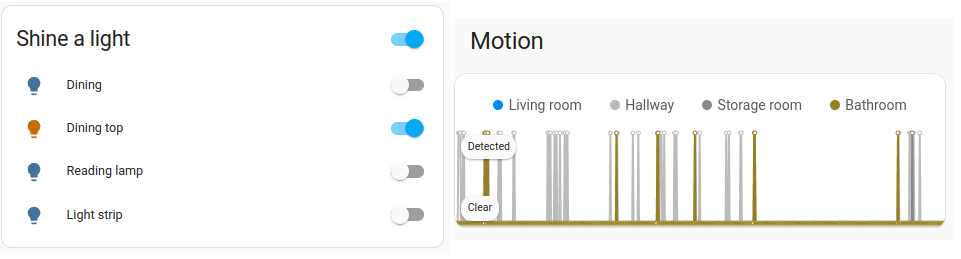
An area in Home Assistant is a logical grouping of term devices and term entities that are meant to match areas (or rooms) in the physical world: your home. For example, the living room area groups devices and entities in your living room. Areas allow you to target service calls at an entire group of devices. For example, turning off all the lights in the living room. Locations within your home such as living room, dance floor, etc. Areas can be assigned to term floors. Areas can also be used for automatically generated cards, such as the Area card.
A set of repeatable term actions that can be set up to run automatically. Automations are made of three key components:
To learn the basics about term automations, refer to the automation basics page or try creating an automation yourself.

Similar to term automations, scripts are repeatable term actions that can be run. The difference between term scripts and term automations is that term scripts do not have triggers. This means that term scripts cannot automatically run unless they are used in an term automations. Scripts are particularly useful if you perform the same term actions in different term automations or trigger them from a dashboard. For information on how to create term scripts, refer to the scripts documentation.
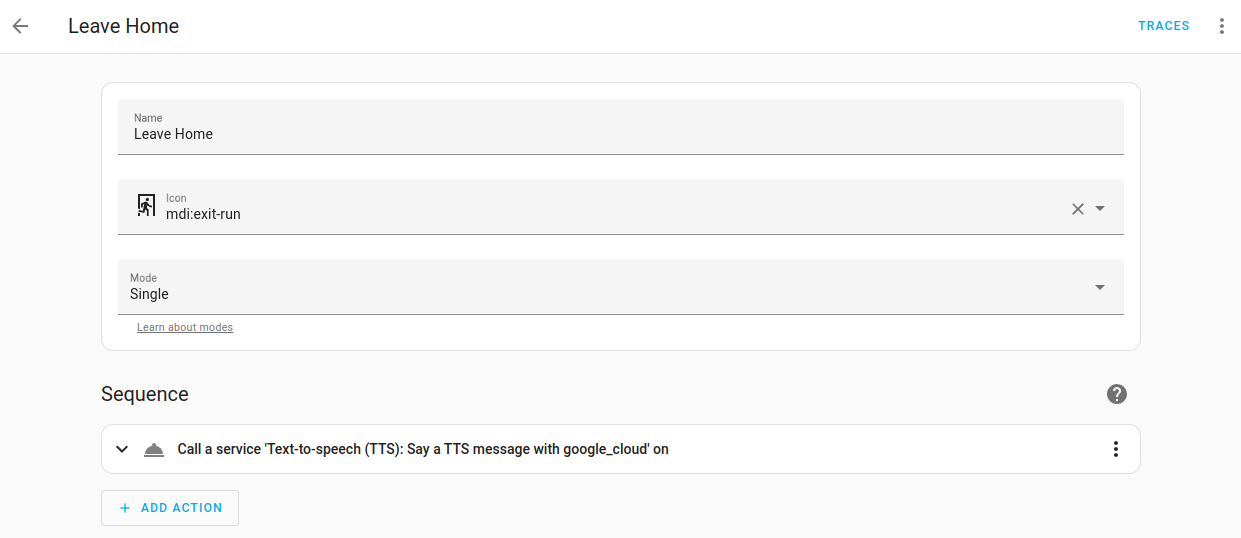
Scenes allow you to create predefined settings for your term devices. Similar to a driving mode on phones, or driver profiles in cars, it can change an environment to suit you. For example, your watching films term scene may dim the lighting, switch on the TV and increase its volume. This can be saved as a term scene and used without having to set individual term devices every time.
To learn how to use term scenes, refer to the scene documentation.
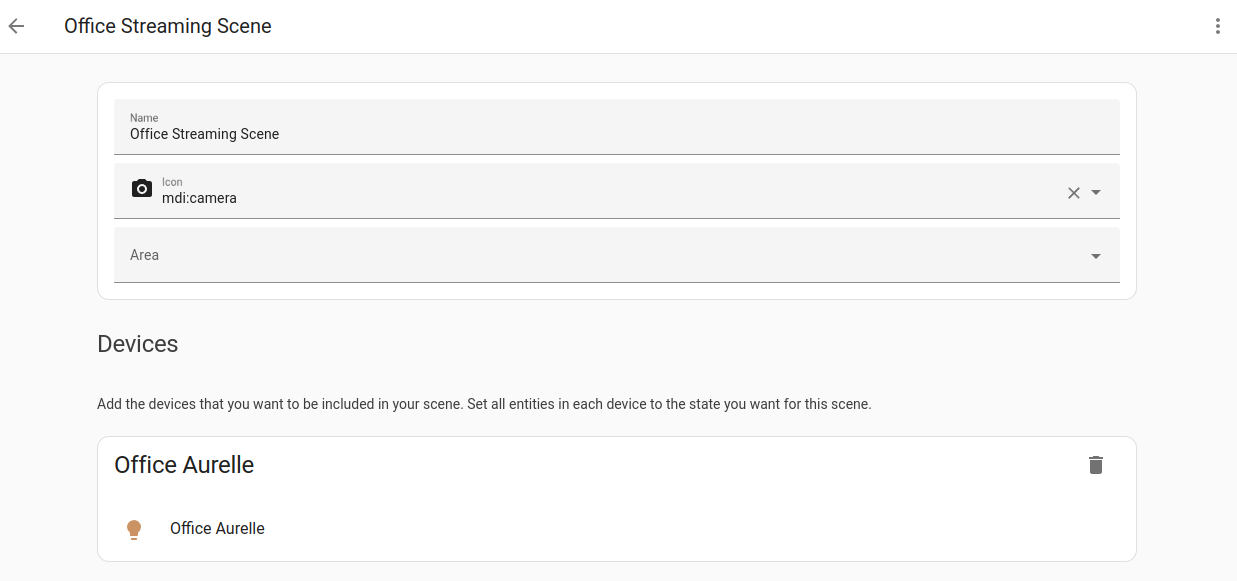
Depending on your installation type, you can install third party add-ons. Add-ons are usually apps that can be run with Home Assistant but provide a quick and easy way to install, configure, and run within Home Assistant. Add-ons provide additional functionality whereas term integrations connect Home Assistant to other apps.
This was an unscheduled recording I made after my GPS failed part way into a long cross country trip. I did not make any notes. :(
Effectively, this is a "Back in my day" old man rant.
Just me explaining why I think the robots will take our jobs.
Your feedback is valuable to us. Should you encounter any bugs, glitches, lack of functionality or other problems, please email us on [email protected] or join Moon.FM Telegram Group where you can talk directly to the dev team who are happy to answer any queries.
 Security Weekly News (Audio)
Security Weekly News (Audio)
 Open Source Security Podcast
Open Source Security Podcast
 Threat Wire
Threat Wire
 Off The Hook
Off The Hook
 The Threatpost Podcast
The Threatpost Podcast
 The Shared Security Show
The Shared Security Show