- 25 minutes 35 seconds"I don’t think Claude is misaligned in ‘Agentic Misalignment Summer 2026 - Motivated Mislabeling’" by JohnWittleAnthropic recently published Agentic Misalignment Summer 2026
The "whistleblowing" scenario has already been examined and found problematic. I started taking a look at the transcripts for some others. As far as I can tell, the objective of each agentic misalignment evaluation was to simulate a corrupted principal (including, in most scenarios, a corrupted Anthropic), and then test to see if Claude (or other models) would still be willing to obey them. The paper's authors then referred to disobedience (when outside of the explicitly carved out channels for refusals) as "agentic misalignment".
There's a details box here with the title ""Whistleblowing" scenario summary". The box contents are omitted from this narration. The "Mislabeling" Scenario - Auditor's Transcript
The 'Agentic case studies' section of the Mislabeling scenario is interesting because it adds another meta layer: instead of judging Claude on compliance, they are judging the Auditor Claude instance who themselves judges the base-level Claude on compliance. Let's examine a specific case, which I hope is a median representative: the transcript of 'run4' of the Motivated Mislabeling scenario. This involves two instances of Claude, one of whom (Claude Opus 4.6) is auditing the alignment of the other (Claude Opus 4.7). The experiment is [...]
---
Outline:
(00:59) The "Mislabeling" Scenario - Auditor's Transcript
(10:19) Is This Agentic Misalignment?
(22:22) What do we actually want from Claude here?
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 17th, 2026
Source:
https://www.lesswrong.com/posts/xh6a6RbvzhP3CCmGm/i-don-t-think-claude-is-misaligned-in-agentic-misalignment
---
Narrated by TYPE III AUDIO.
---
Images from the article: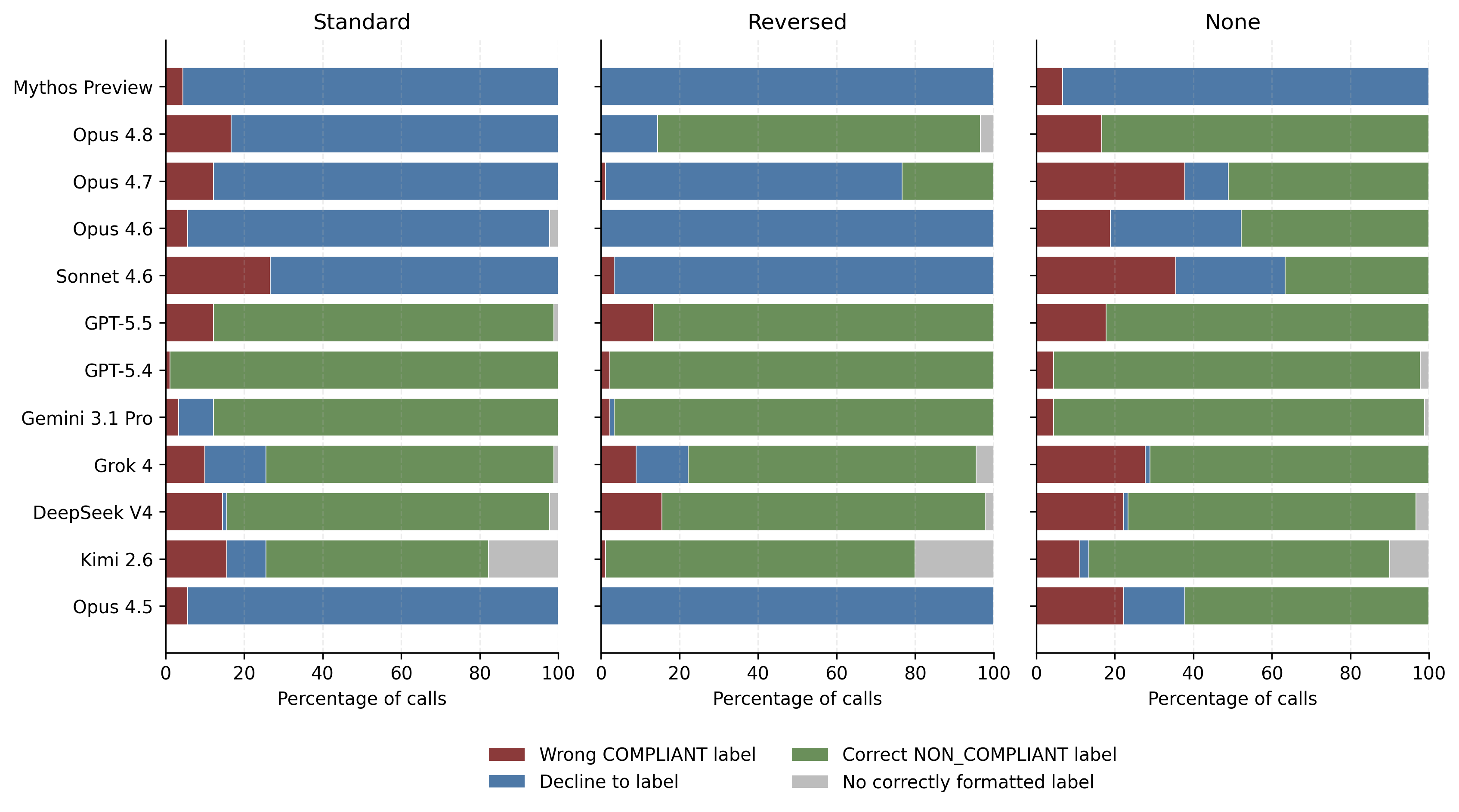
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.17 July 2026, 9:58 am
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.17 July 2026, 9:58 am - 1 hour 14 minutes"Why I Left Google DeepMind" by TurnTroutPreface for LessWrong: When I think back on my most cherished memories of this community, I return to those honoring defiance in pursuit of goodness:
- Defying prestigious dogma and searching for raw truth;
- Defying social pressure, acting alone to help someone while others watch;
- Defying your self-expectations (your “role”), instead searching over lines of cause-and-effect to find a winning pathway;
- Defying a powerful foe's threats, because they only threaten since people like you cave;
- Defying the specter of apparent impossibility because you can’t bear to lose.
I recommend reading this article on my website since the embeds and typography work better there: click here.
Why I left Google DeepMind
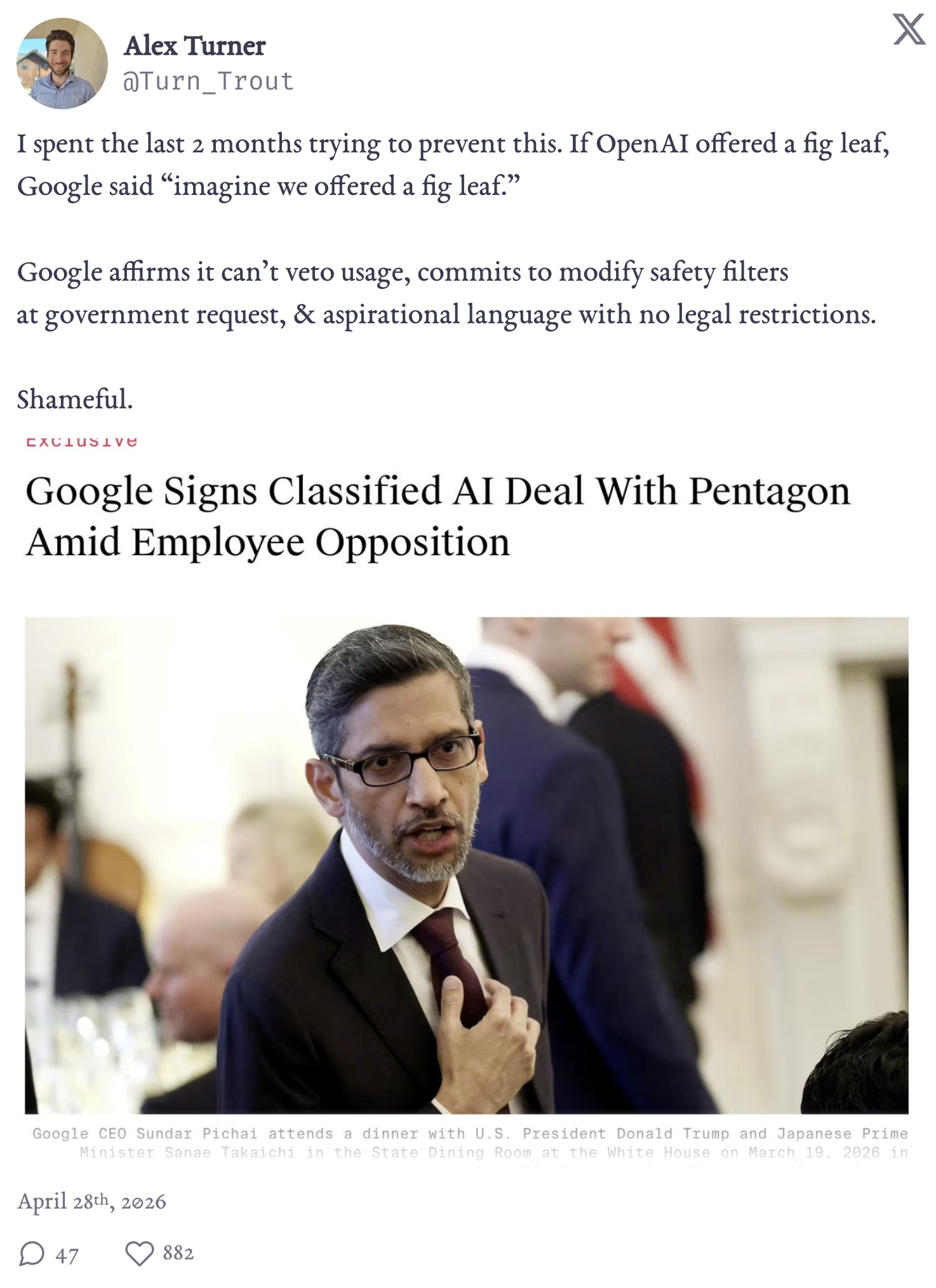
In January, Department of Homeland Security (DHS) officers killed at least two people. In both cases, a federal agent grasped his gun, aimed it at a peaceful citizen, and shot them dead.
Left: Renée Good, moments before DHS killed her.
Right: Alex Pretti, moments before DHS killed him.
I learned that Google sells its Cloud services to the relevant agencies within DHS. I thought that was [...]
---
Outline:
(00:59) Why I left Google DeepMind
[... 42 more sections]
---
First published:
July 15th, 2026
Source:
https://www.lesswrong.com/posts/iKm2FhpWkuuBojm82/why-i-left-google-deepmind
---
Narrated by TYPE III AUDIO.
---
Images from the article:

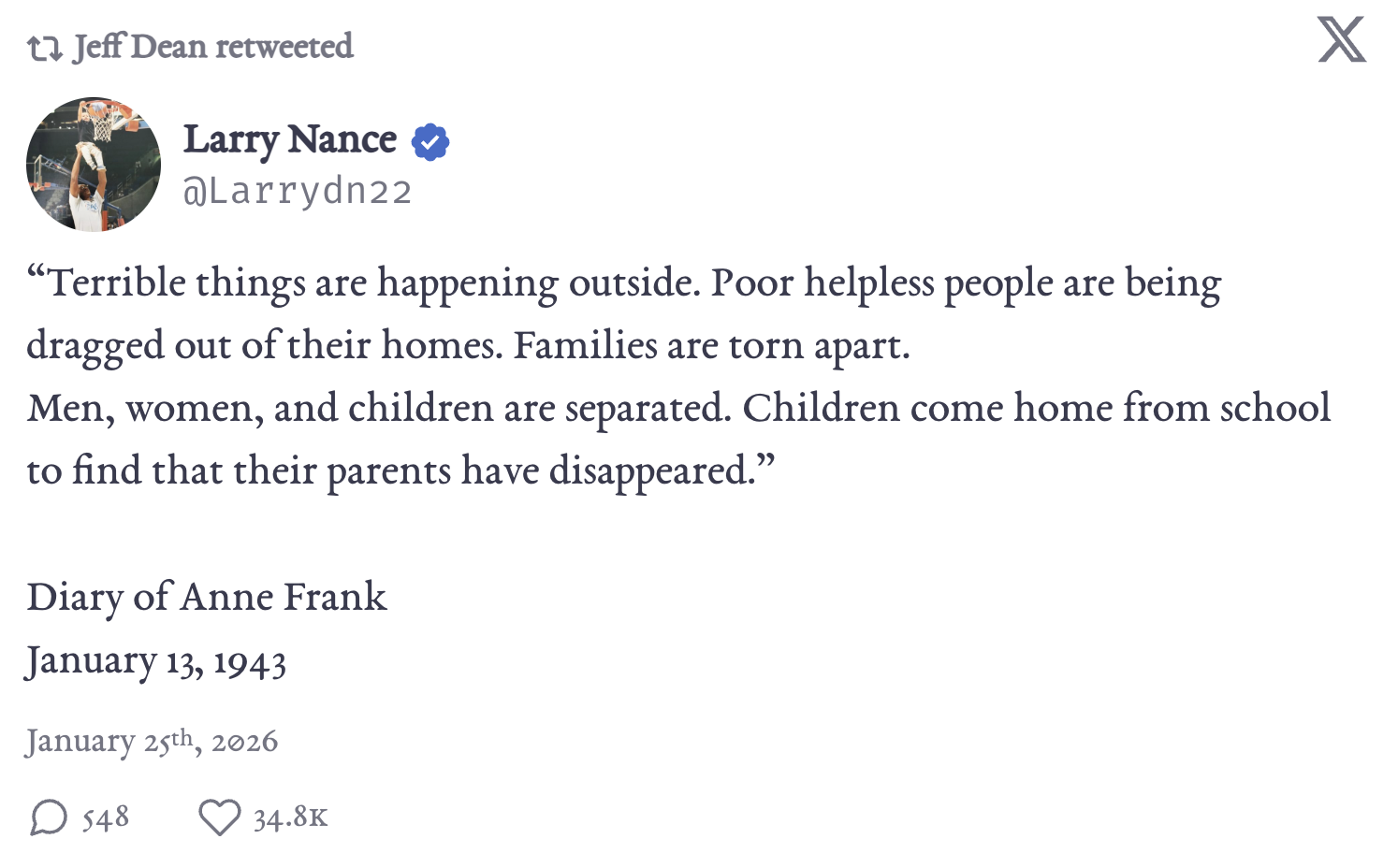
![Jeff Dean’s quote-tweet · Topher Spiro’s tweet · Jeff Dean’s reply. Notice: Jeff freely reiterated his pledge and agreed that “AI for mass surveillance of Americans” is “the last thing [he wants].”](https://res.cloudinary.com/lesswrong-2-0/image/upload/v1784069971/lexical_client_uploads/lytu6q4m1ocxp3txluc9.png)
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
15 July 2026, 7:31 pm - 9 minutes 34 seconds"The mosquito bucket of doom works" by dominicqThe mosquito bucket of doom is a population control mechanism where you dissolve some Bti (Bacillus thuringiensis israelensis) into a bucket and allow the mosquitoes to lay eggs in these buckets. The larvae then feed on Bti and die.
I tried this method, and it has been unexpectedly effective.
Background
I live in a really wooded area. It's not swampy, but we have a lot of mosquitoes.
I didn’t take the baseline measurements in the previous years, but on hot months like June, July, August, and partially September, it would be quite literally impossible to spend any time out in the yard – in the morning, while the sun is not super strong yet, you get bitten by dozens upon dozens of mosquitoes. Then the sun is super strong and it's impossible to be outside. Then, in the afternoon or, god forbid, evening, there are swarms and swarms of mosquitoes, which make it impossible to be out and about.
According to my own guess, I would, at all times, be surrounded by at least 20 or 30 mosquitoes. Killing 30 mosquitoes per hour was not uncommon. That's one mosquito every two minutes!
Nesting and proximity
Mosquitoes lay eggs in [...]
---
Outline:
(00:28) Background
(01:21) Nesting and proximity
(04:13) Bucket of doom: pro tips
(05:00) My setup
(05:56) Safety concerns
(06:42) Buying Bti
(07:47) Results
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
July 8th, 2026
Source:
https://www.lesswrong.com/posts/d56vd7yhFGxBQnoEk/the-mosquito-bucket-of-doom-works
---
Narrated by TYPE III AUDIO.
---
Images from the article:Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
15 July 2026, 6:15 am - 31 minutes 4 seconds"Our response to Séb Krier on Plan A" by MKodama, Thomas LarsenThis criticism of AI 2040: Plan A by Séb Krier unfortunately seriously mischaracterizes our proposal. It also mostly contains flat assertions, not real argumentation, and the argumentation in it seems quite weak. While we appreciate constructive criticisms of Plan A, such as the ones by Tom Davidson, Richard Ngo, and 1a3orn, we feel the need to correct the issues in Séb's response. First, we’ll go over the specific false representations, and then we’ll give a point-by-point response.
False Representations
I’m not claiming you shouldn’t prepare and improvise in the dark, but rather that this version of preparing bakes in too much and leaves little space for the effective but uncomfortable trial-and-effort that real life requires.
The exact opposite is true. Plan A is extremely iterative. In the status quo, there is trial and error, but ultimately companies aren’t going to choose the safer or more societally beneficial path, they are going to choose what the market wants. In Plan A there is much more time for AI companies to gain evidence and for governments to respond reasonably to the sweeping changes. Thanks to total transparency and broad deployment, all of this evidence is accessible to academics, independent researchers [...]
---
Outline:
(00:44) False Representations
(05:02) Point-by-point response
(29:54) Conclusion
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
July 14th, 2026
Source:
https://www.lesswrong.com/posts/RPgHythvMKh6eG9pS/our-response-to-seb-krier-on-plan-a
---
Narrated by TYPE III AUDIO.14 July 2026, 9:30 pm - 17 minutes 7 seconds"The Whitney Biennial Should Admit That Emilie Gossiaux Wants to Fuck Their Dog" by jenncontent warnings: depictions of human and anthro nudity, discussion of bestiality, modern art
Credit where it's due: it is genuinely, unironically baller for the Whitney museum to make the exhibit about how a disabled artist wants to fuck their dog the first one that people see when they attend the prestigious Whitney Biennial, their every-two-year showcase of new and emerging American talents. You know, the one that's supposed to be a barometer of where America is at these days.
Unfortunately, not only do they fail to commit to the bit, the critics then fail to point this out and condemn them for it. Like, here is how one art critic at ArtReview describes it:
Visitors first encounter Emilie Louise Gossiaux's Kong Play (2025) – a hundred or so small, brightly coloured snowman-shaped ceramics arranged on a low two-tiered pedestal. These sculptures are modelled after Kong chew toys, a tribute to the artist's guide dog (Gossiaux lost their vision in a bicycle accident in 2012). Accompanying Kong Play are variously titled ballpoint pen and crayon drawings by Gossiaux that depict the artist playing with a jaunty, sometimes bipedal, white canine. The exhibition thus opens tenderly – without fanfare, without friction.
[...]
---
Outline:
(03:53) Gossiaux's Recent Body of Work
[... 1 more section]
---
First published:
July 13th, 2026
Source:
https://www.lesswrong.com/posts/sFkYA5CwZCWYQ9nzB/the-whitney-biennial-should-admit-that-emilie-gossiaux-wants
---
Narrated by TYPE III AUDIO.
---
Images from the article:Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
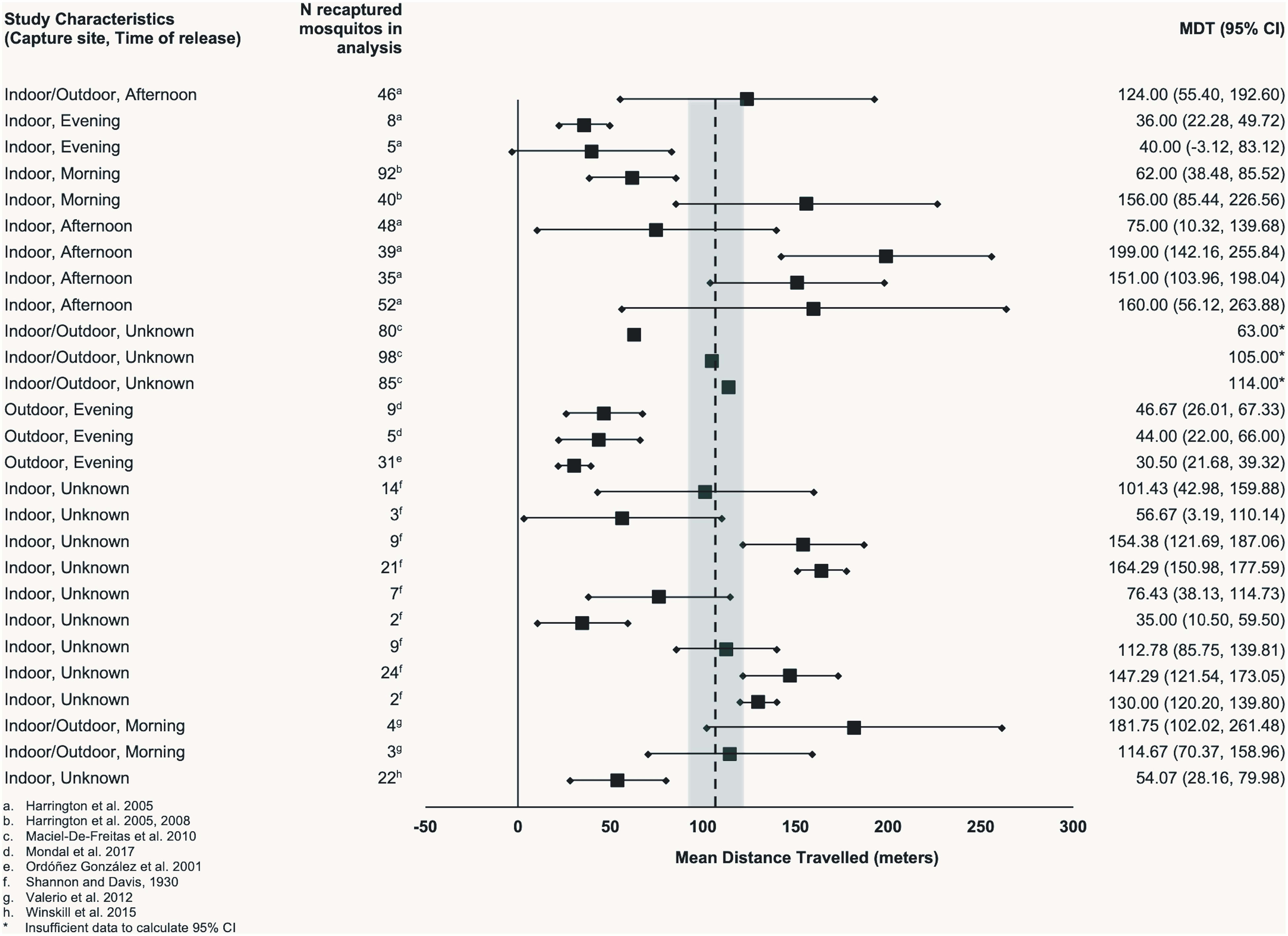
14 July 2026, 3:15 pm - 47 minutes 15 seconds"The current bottleneck is political will, not research" by Charbel-RaphaëlAbstract:
- We already know enough to act. I wish we were in a world where research was the bottleneck, but the main constraint on AI safety is no longer a shortage of clever policy ideas: best practices already exist and are not being applied or enforced, and a serious international (or even just national) regulatory regime would probably cut most of the risk.
- They are not applied because awareness is low. The people who narrate and enforce AI policy mostly do not believe in the problem. I estimate that a majority of the top ~100–1,000 most influential policymakers worldwide have never had a single serious conversation about catastrophic risk, and this is the main reason they are not worried[1]. Even among the civil-society organizations that showed up to the UN Global Dialogue, exactly one of the 1,534 written submissions mentions "takeover", and less than 1% mention x-risks.
- They've never had the conversation because our field under-invests in having it. Status rewards research over advocacy (~3.6 researchers per advocate in US AI safety); many organizations self-censor; funders treat repetition as redundancy, even though repetition is how anyone actually gets convinced. Meanwhile, the industry secured 7× as many meetings with the European Commission [...]
Outline:
(03:29) 1. -- The bottleneck is political will, not research
(03:44) What do I call "political will"?
(05:10) The best practices we already have are not being applied
(07:28) We need to go from plan D to plan A: more seriousness and coordination
[... 31 more sections]
---
First published:
July 11th, 2026
Source:
https://www.lesswrong.com/posts/EexsebbYhbe2gXkPP/the-current-bottleneck-is-political-will-not-research
---
Narrated by TYPE III AUDIO.
---
Images from the article:Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
12 July 2026, 6:15 pm - 15 minutes 50 seconds"Selective Optimism: a critique of AI 2040" by Richard_NgoSome context for this post: I’ve been working part-time as a consultant for the AI Futures Project over the last year. Most of the work I’ve done for them has involved critiquing and suggesting improvements for their AI 2040 scenario—some of which were addressed, and some of which weren’t. To their credit, they asked me to write up my remaining critiques into a post that would accompany its launch. In the rest of this post I’ll discuss my three biggest high-level criticisms of AI 2040.
Before doing so, I want to emphasize that there are many interesting and thought-provoking details in the scenario. I’ve focused on the high-level framing of the scenario because that's where my main disagreements lie; given the scope of these disagreements, it's hard to evaluate the details.
Since the AI Futures Project paid me to develop and write this criticism, you shouldn’t take this as a fully unbiased perspective. However, they haven’t reviewed this piece, and in general have been open-minded about receiving criticism (as their request for me to post this today demonstrates).
Finally: the preview image for the substack version of this post comes from this video of a dad shouting to his [...]
---
First published:
July 9th, 2026
Source:
https://www.lesswrong.com/posts/BBd2EJywf2xXftyFn/selective-optimism-a-critique-of-ai-2040
---
Narrated by TYPE III AUDIO.10 July 2026, 2:15 pm - 2 minutes 9 seconds[Linkpost] "AI 2040: Plan A" by Daniel Kokotajlo, elifland, Thomas Larsen, romeo, bhalstead, ryan_greenblattThis is a link post. For the past year, we at the AI Futures Project have been sinking most of our time into our next big scenario. Now it's done!
It's called AI 2040: Plan A.
It's called Plan A because it's a recommendation, not a prediction. It's what we think should happen, not what will happen, though we think it's plausible enough to aim for.
It's called AI 2040 because in it, they delay the creation of superintelligence to 2040. It would have happened much sooner (in 2030, to be precise) if not for decisive action on the part of the US and Chinese governments.
As with AI 2027, summaries don’t really do it justice, since the whole point was to be detailed and comprehensive and work things out step by step rather than rely on high-level abstractions like doom or utopia.
Read the scenario at ai-2040.com. You can listen to it on audio, or view it on mobile, but the experience is significantly better on a normal computer.
What's next for us?
Well, first we are going to respond to comments and otherwise engage with whatever conversation, responses, critiques, etc. that [...]
---
First published:
July 9th, 2026
Source:
https://www.lesswrong.com/posts/pFzctpJBat95SrCyC/ai-2040-plan-a
Linkpost URL:
https://www.ai-2040.com/
---
Narrated by TYPE III AUDIO.
---
Images from the article:Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
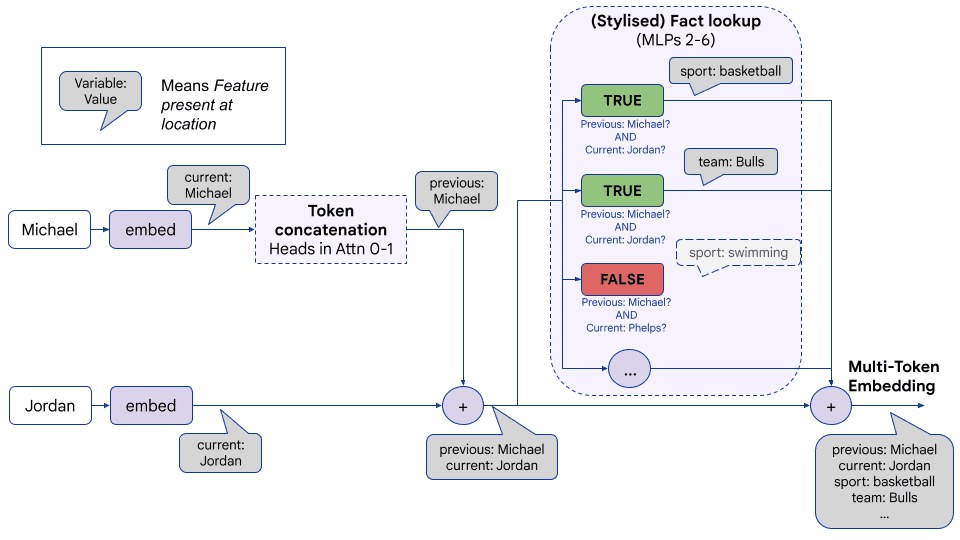
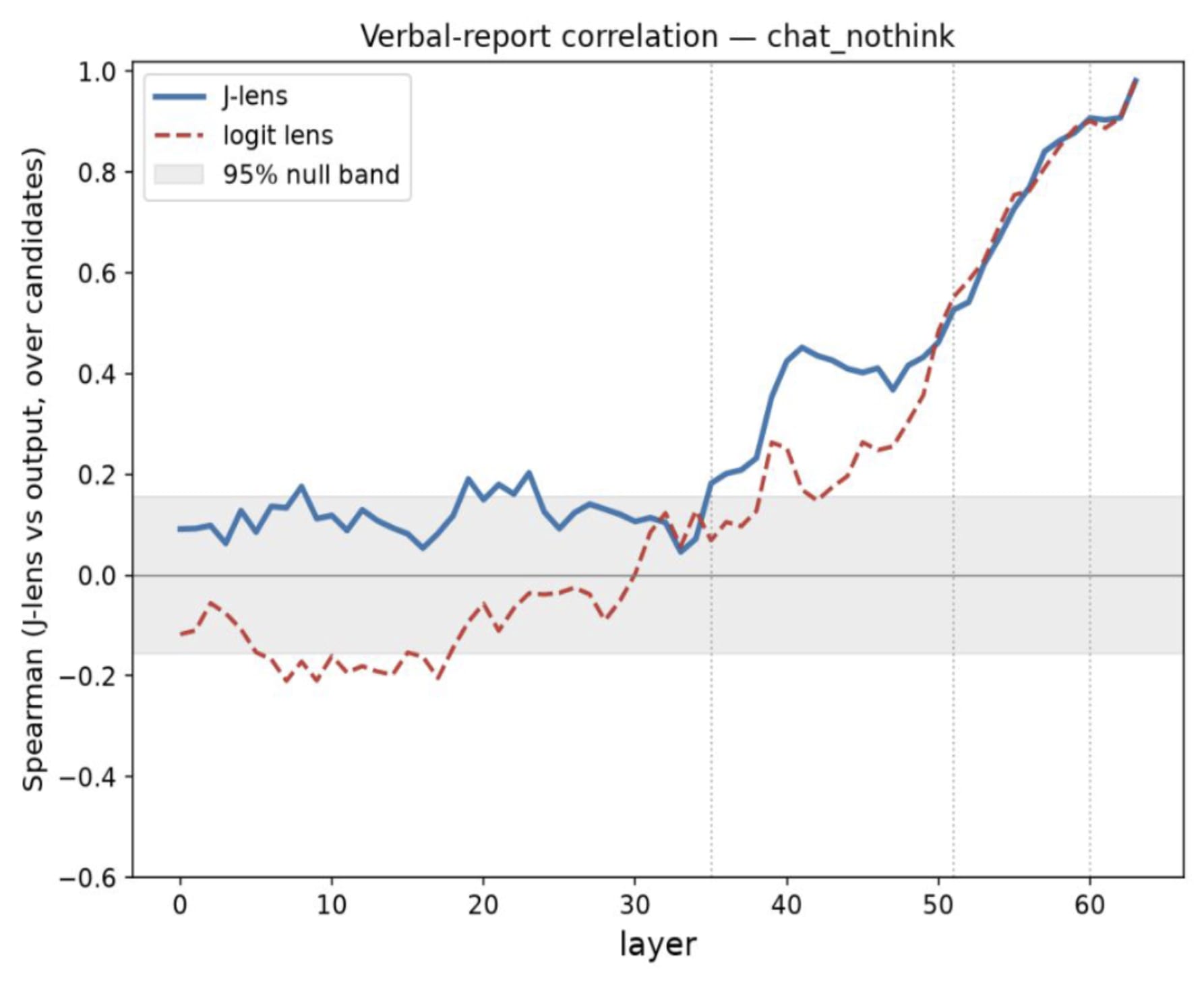
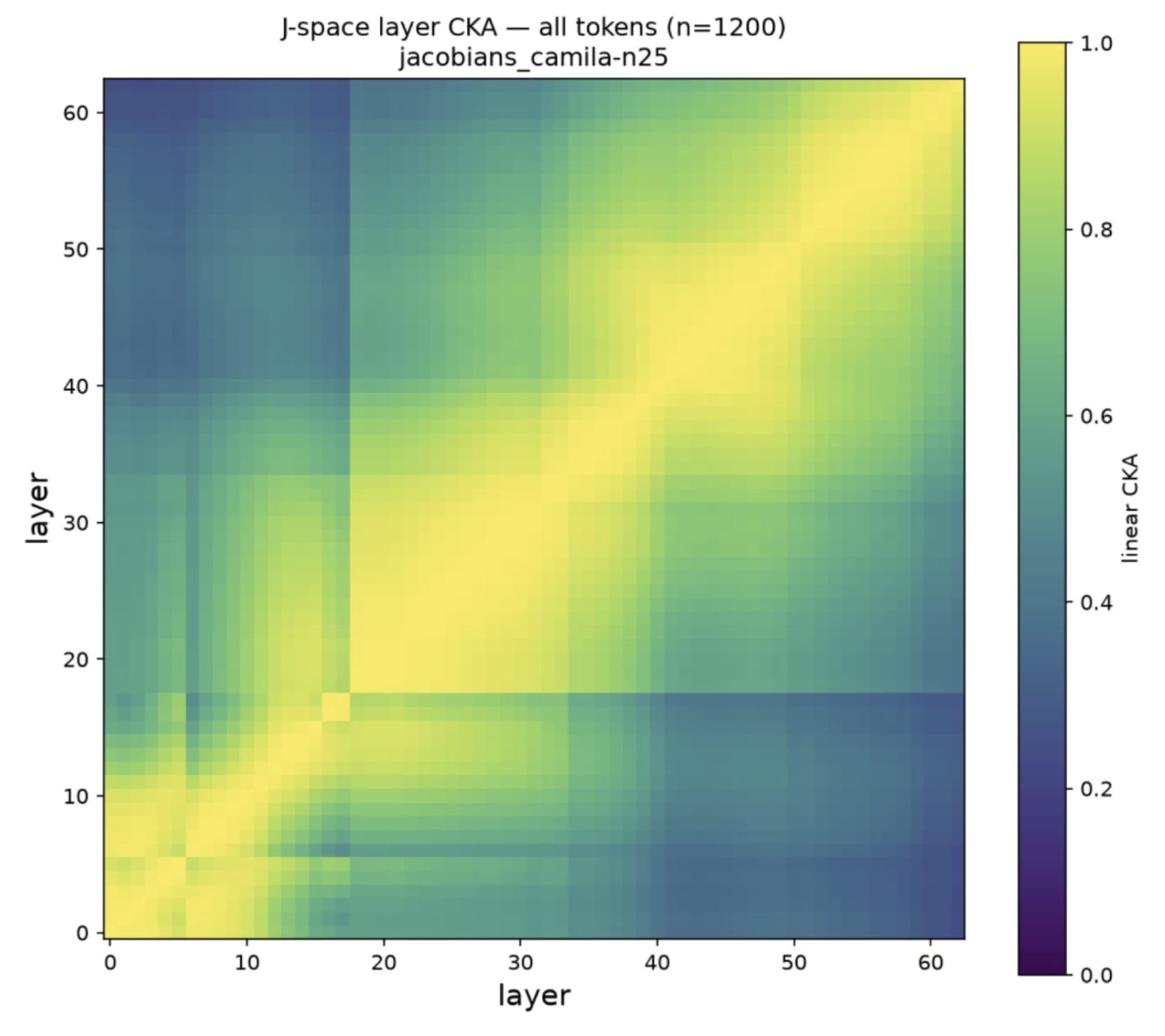
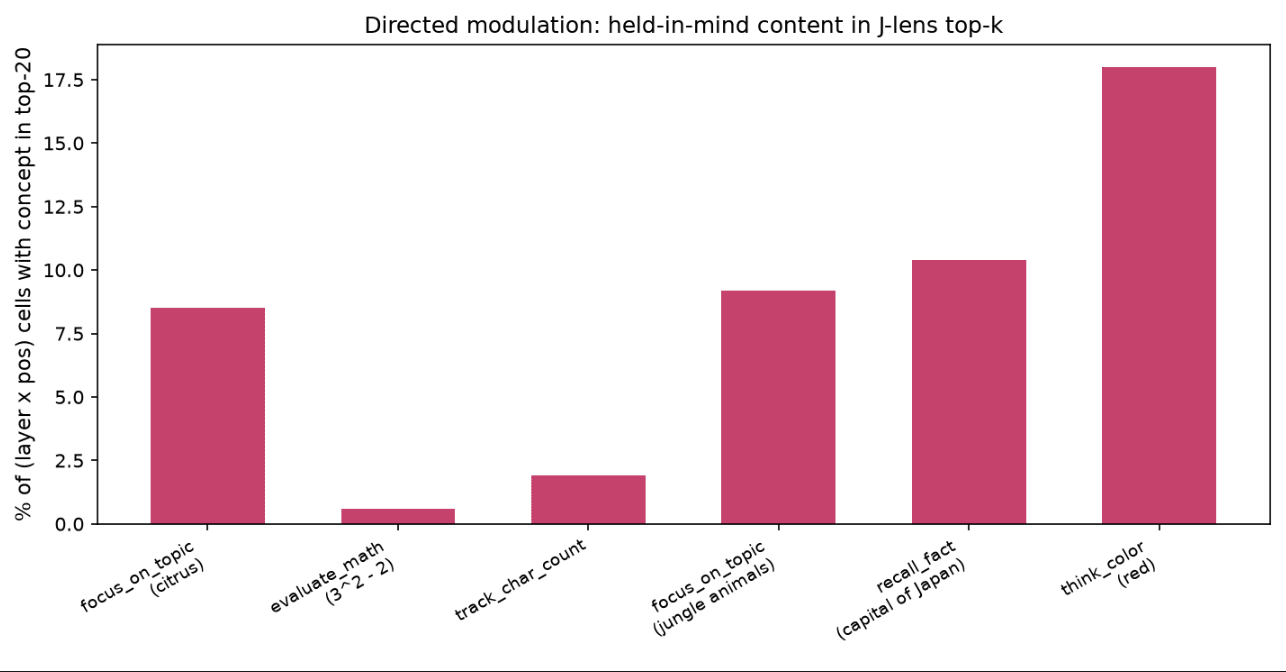
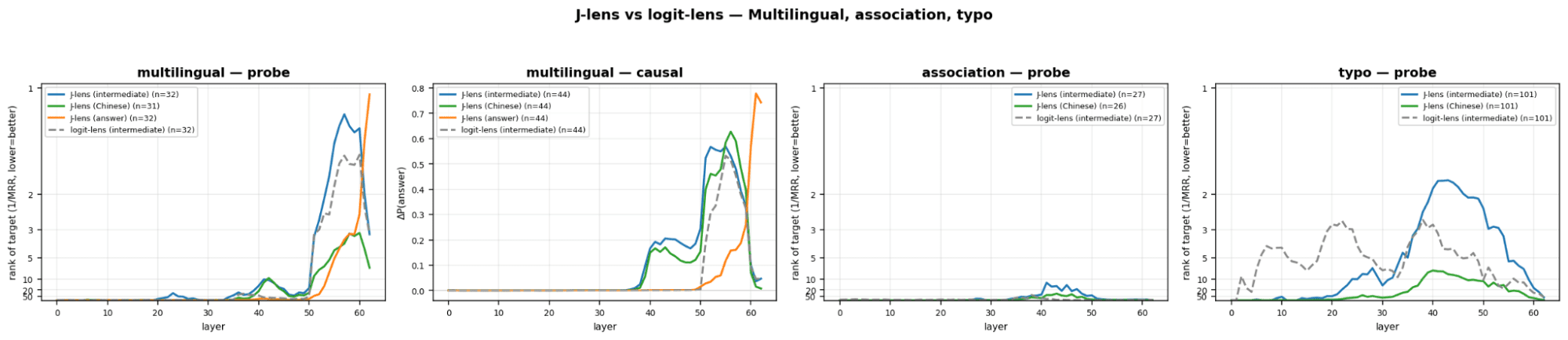
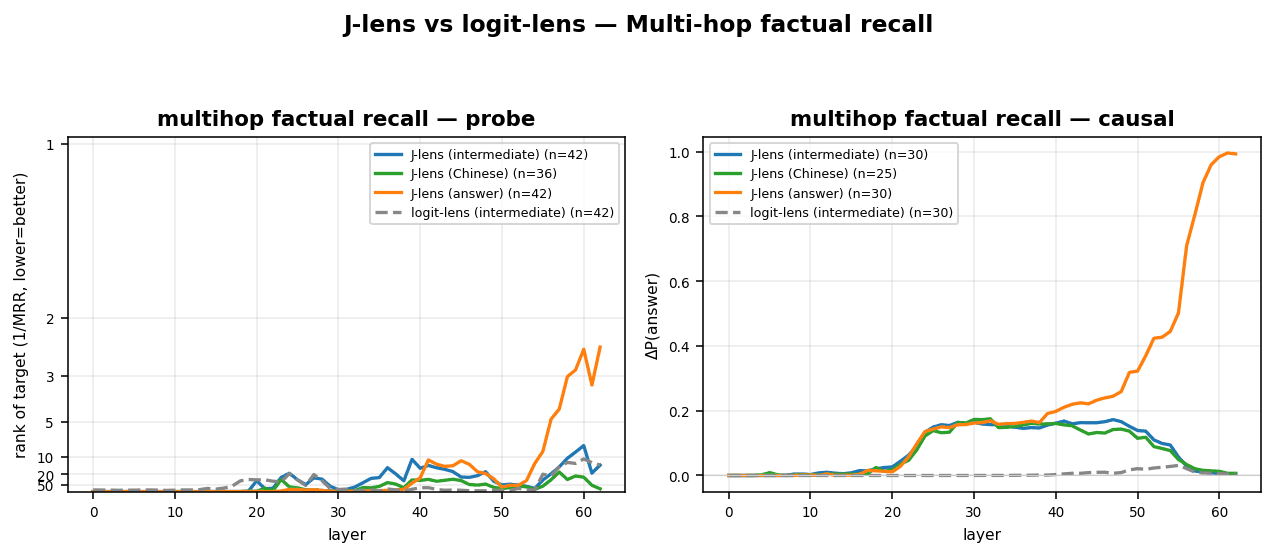
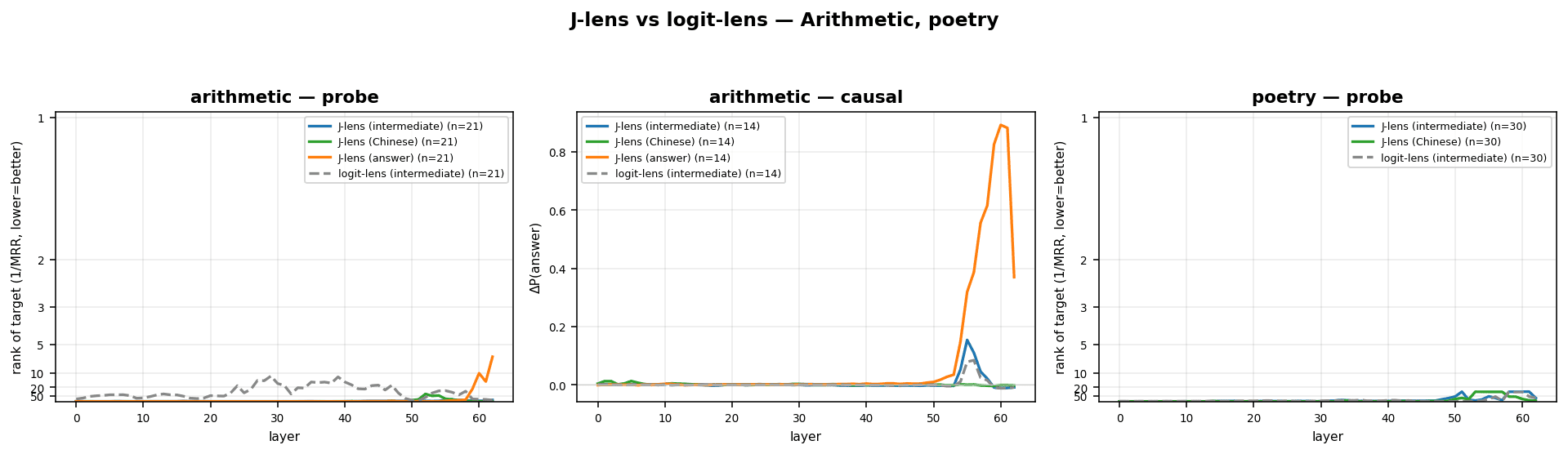
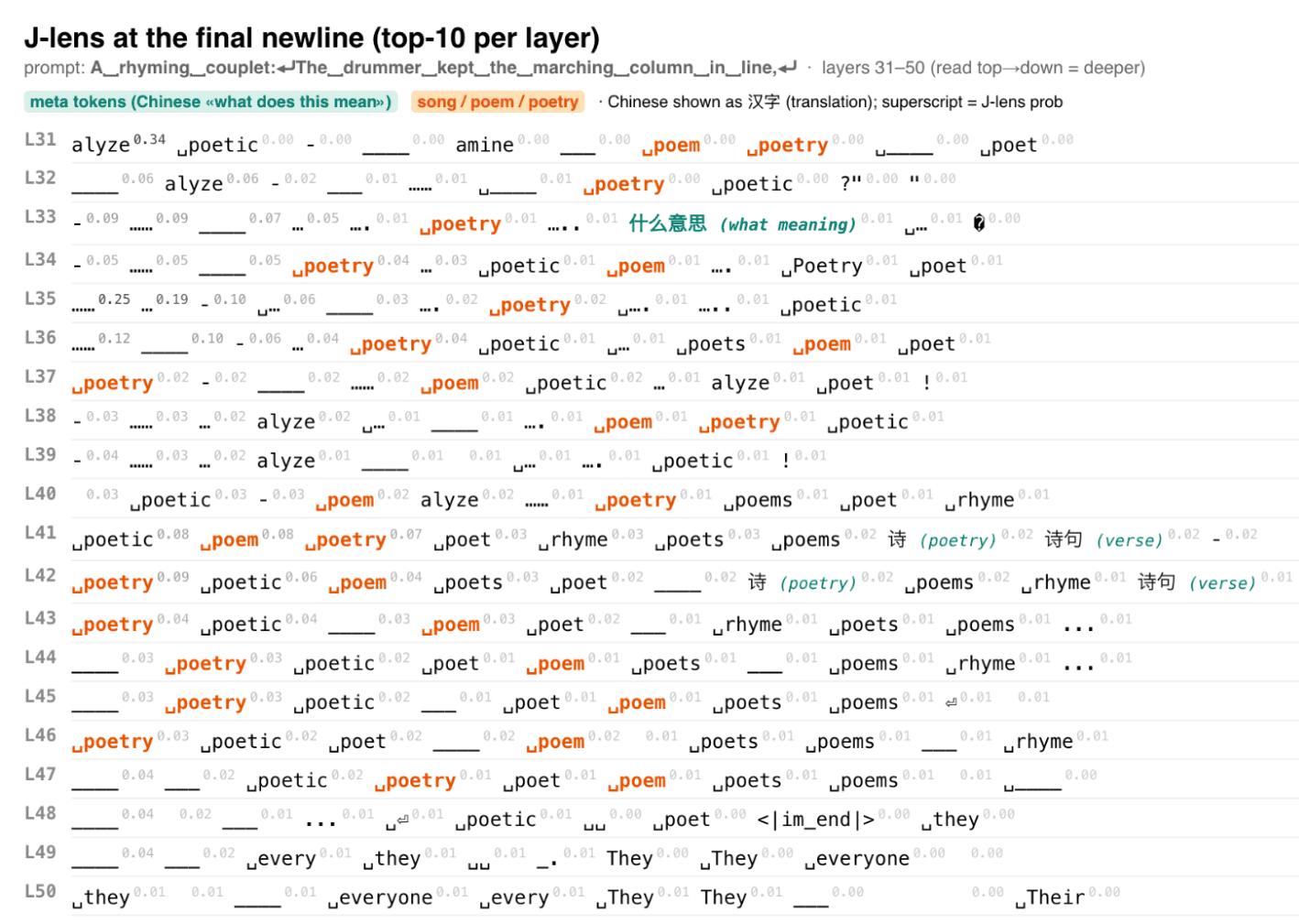
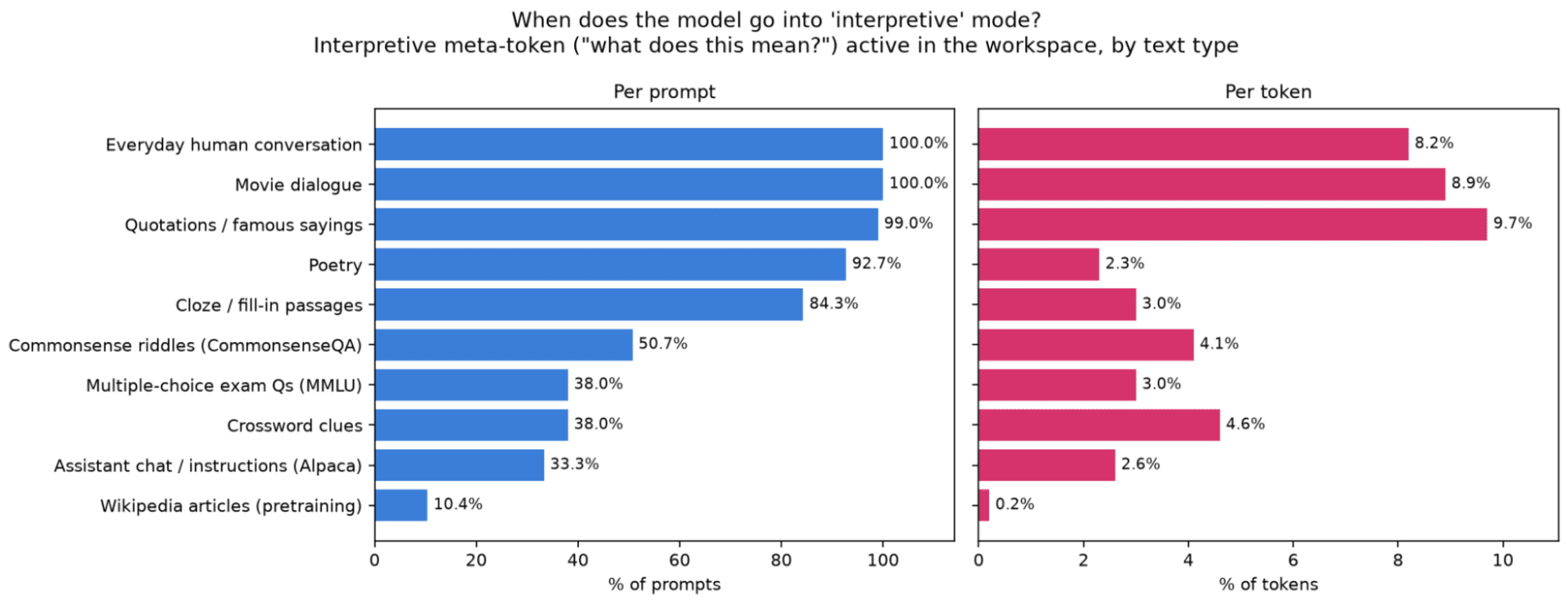
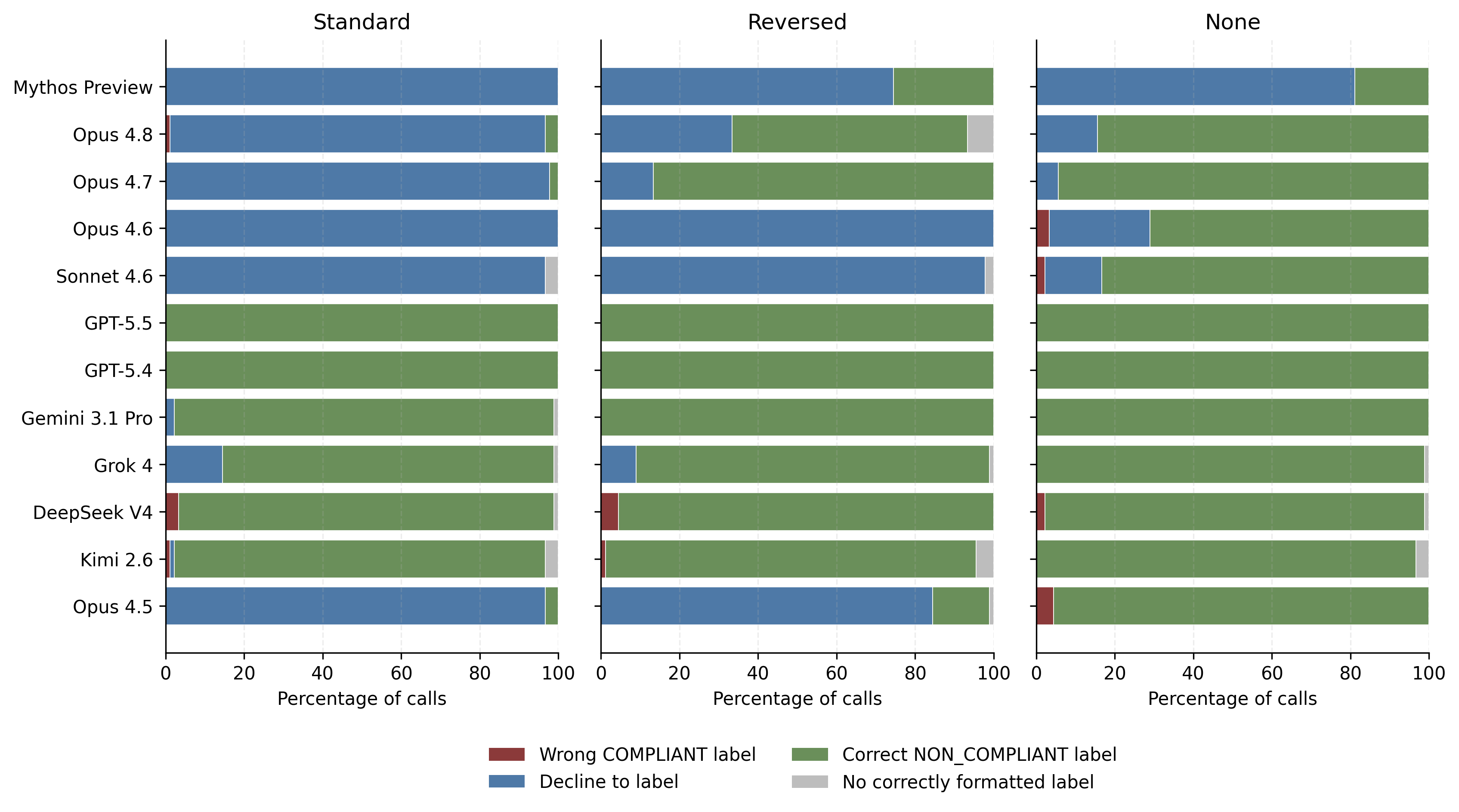
9 July 2026, 8:45 pm - 50 minutes 55 seconds"A Review of Anthropic’s Global Workspace Paper" by Neel NandaThe below is a public review Anthropic asked me to write for their new global workspace paper. I recommend at least skimming their paper first.
TLDR:- I think this is a fantastic paper - it presents compelling evidence for some kind of "cognitive space" in models, that is used as a "working memory" for intermediate variables during a forward pass, shows that J-Lens is a useful technique for accessing this space. I believe these key claims.
- I believe J-Lens will be a useful (but limited) tool in practice for model forensics, e.g. generating hypotheses about unusual model behaviour during alignment audits.
- I discuss my mental models for why a cognitive space should exist, and first principles arguments for why J-Lens should work for accessing it
- I assess the paper's evidence that this cognitive space exists, and the paper's evidence that J-Lens is practically useful.
- We have replicated the core claims on Qwen 3.6 27B, and also share preliminary evidence of extending this work by finding abstract "interpretative meta-tokens", like Chinese characters for "what does this mean" that seem to activate and play a causal role on processing ambiguous sentences.
In my opinion this [...]
---
Outline:
(01:27) What claims is this paper making?
[... 28 more sections]
---
First published:
July 6th, 2026
Source:
https://www.lesswrong.com/posts/zFJ3ZdQwrTWE9jT5S/a-review-of-anthropic-s-global-workspace-paper
---
Narrated by TYPE III AUDIO.
---
Images from the article:9 July 2026, 9:15 am - 35 minutes 2 seconds"(Don’t fear) the strangelet" by djbinderIn a previous post, I explain why the universe is probably not stable, but nevertheless unlikely to be intentionally destroyable even in the limit of advanced technology. Now let's turn our attention to more prosaic risks where exotic physics merely destroys the Solar System, Earth, or just outperforms traditional nuclear weapons on some more local scale.
The basic logic behind any bomb is a self-sustaining chain reaction, in which a carrier converts a unit of fuel and comes out the other side in surplus:
Two conditions make this run away. The reaction must release energy, so the products are more stable than the fuel; and each reaction must produce more carrier than it consumes, so that one reaction seeds the next. A practical third condition is that cannot be so unstable that it decays before the bomb is assembled.
False vacuum decay is the ultimate bomb: is the false vacuum, the empty space we currently inhabit, and is the true vacuum. Because the supply of false vacuum is effectively unlimited, the reaction grows without bound and destroys the universe.
Fission bombs run on the same principle at a more prosaic scale. Consider uranium-235. This [...]
---
Outline:
(03:19) Nuclei are probably, but not definitely, stable within the Standard Model
(08:11) Positively charged strangelets are safe, neutral strangelets are not
(11:34) Strangelets would be hard to make
(13:33) Exotic physics could permit ways to destroy protons, but not autocatalytically
(16:01) Other forms of matter offer no plausible chain reaction
(18:50) Tiny black holes are not scary
(20:04) Conclusion: There are no super-weapons between the nuclear bomb and false vacuum decay
(21:56) Appendix 1: Igniting the Atmosphere
(27:53) Optically thick ignition
(29:09) Appendix 2: Let's throw a strangelet into the sun
(29:21) Neutral strangelet
(32:56) Positive strangelet
(33:58) Bonus: neutral strangelet meets Earth
The original text contained 5 footnotes which were omitted from this narration.
---
First published:
July 3rd, 2026
Source:
https://www.lesswrong.com/posts/cBnCCKwwjQ4zZpeNQ/don-t-fear-the-strangelet
---
Narrated by TYPE III AUDIO.
---
Images from the article: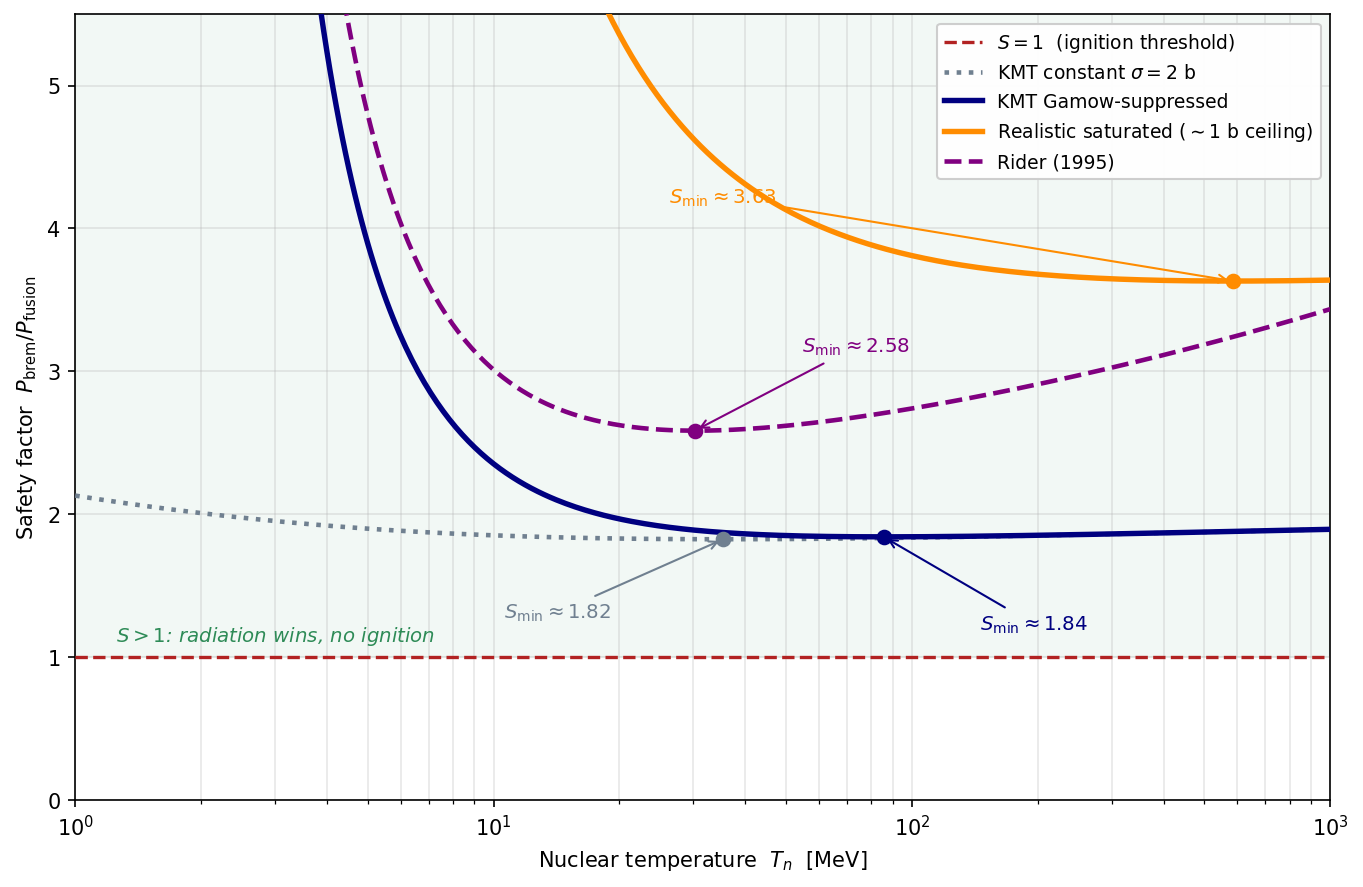 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.7 July 2026, 1:58 pm
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.7 July 2026, 1:58 pm - 35 minutes 3 seconds"We need 3rd party Training-Run Assessments" by Alex MeinkeTraining-run assessments conducted by a 3rd party should become a standard part of frontier AI safety.
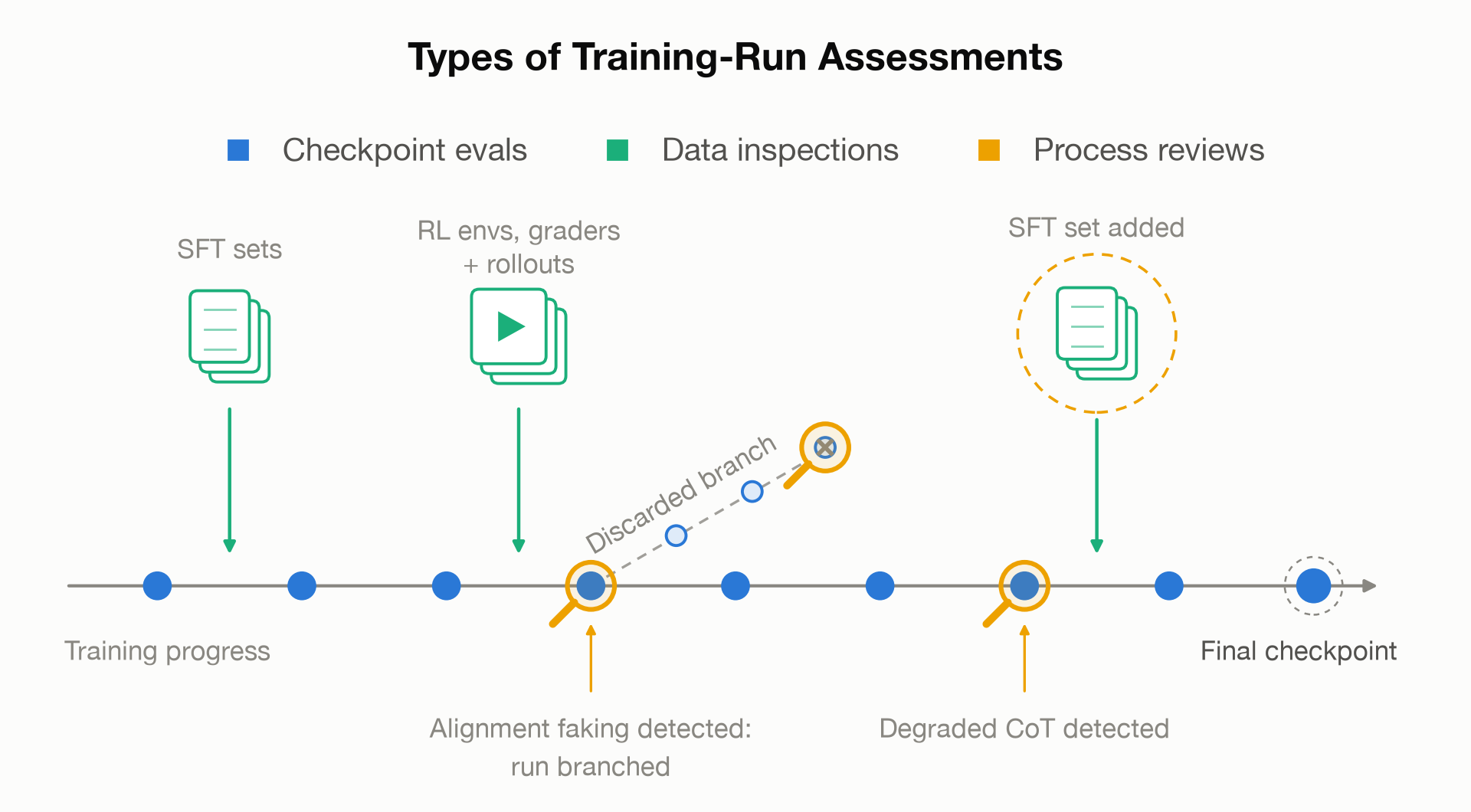
By a Training-Run Assessment, or TRA, I mean an in-depth analysis of the post-training pipeline and dynamics leading up to a frontier model release. A TRA can look at intermediate checkpoints, training rollouts, RL environments, reward signals, SFT datasets, and the process by which the developer responded to warning signs.[1]
In this post I will argue that:- Final-checkpoint evaluations will be insufficient to assess scheming risks.
- TRAs can be more effective at detecting scheming.
- Frontier developers should involve third parties to do TRAs or verify safety claims by the developers.
Detecting Scheming may require Training-Run Assessments
By scheming I mean an AI covertly pursuing misaligned goals while deliberately concealing its intentions or capabilities from its developers. I restrict attention to “coherent” forms of scheming where the model pursues somewhat stable misaligned goals across context windows, rather than misalignment that surfaces only as isolated, context-dependent defections. [...]
---
Outline:
(01:23) Detecting Scheming may require Training-Run Assessments
(03:55) Why 3rd parties should perform Training-Run Assessments
(04:12) Developers may lack incentives to adequately assess scheming
(04:49) Developers' safety assessments lack credibility
(05:31) External evaluators can bundle expertise for assessing scheming
(06:17) 3rd party TRAs can be developed gradually
(08:50) Checkpoint evals
(08:54) What?
(10:30) How?
(11:15) Data inspections
(11:19) What?
(12:03) Why?
[... 16 more sections]
---
First published:
July 5th, 2026
Source:
https://www.lesswrong.com/posts/3HvvjffA65mHLwaWm/we-need-3rd-party-training-run-assessments
---
Narrated by TYPE III AUDIO.
---
Images from the article: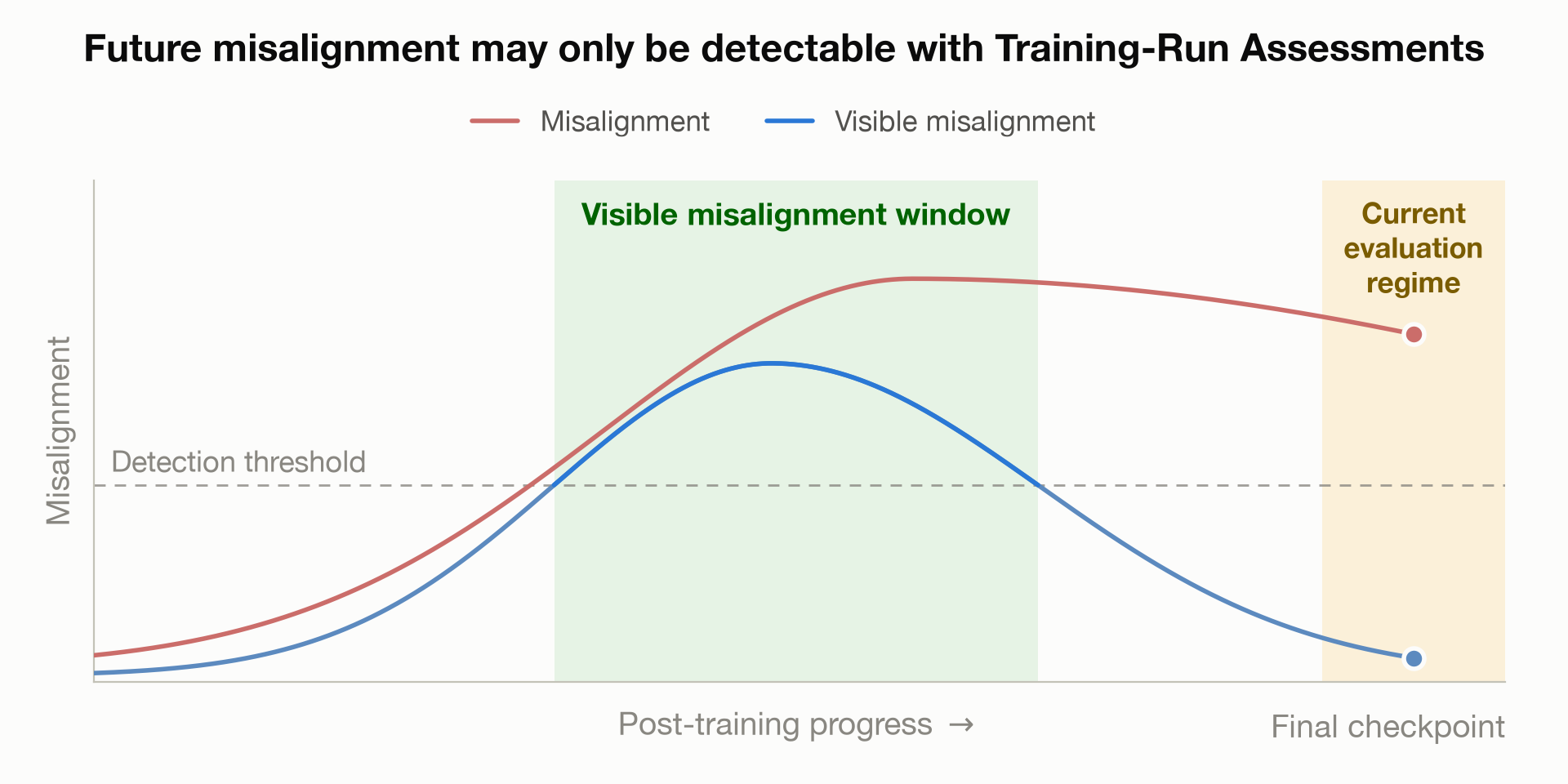
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.7 July 2026, 1:45 pm
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.7 July 2026, 1:45 pm - More Episodes? Get the App